Exploiting Filepicker.io
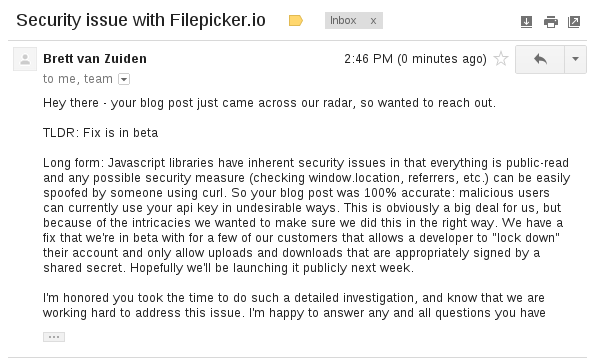
EDIT: I received an email from Filepicker CEO, Brett van Zuiden
Filepicker.io is awesome. It is damn easy to use, and saved me tons of time that would have been wasted trying to create my own (and worse) alternative image uploading support. The API is easy, but still extensively customizable when needed, and gives you all of this control directly from the Javascript call to getFile().
As fanastic as this service is, however, that last bit struck me as odd.
Here is an example call to getFile():
filepicker.setKey('some_awesome_key');
filepicker.getFile(['text/plain','image/jpeg'], {
'maxsize' : 50*1024,
'services' : [
filepicker.SERVICES.COMPUTER,
filepicker.SERVICES.FACEBOOK,
filepicker.SERVICES.GMAIL
]
}, function(response) {
console.log(response);
});Now, the API key is obviously needed. It also makes sense to have the services mapping here, as it doesn’t really concern the backend. However, from a security standpoint I couldn’t see why on earth the maximum upload size and MIME type limiter would be specified client side.
The Javascript file containing their library is located here. The file is obviously minified, however it can easily be ran through jsbeautifier and cleaned up a bit. After about four layers of digging, I gave up and just did a network capture.
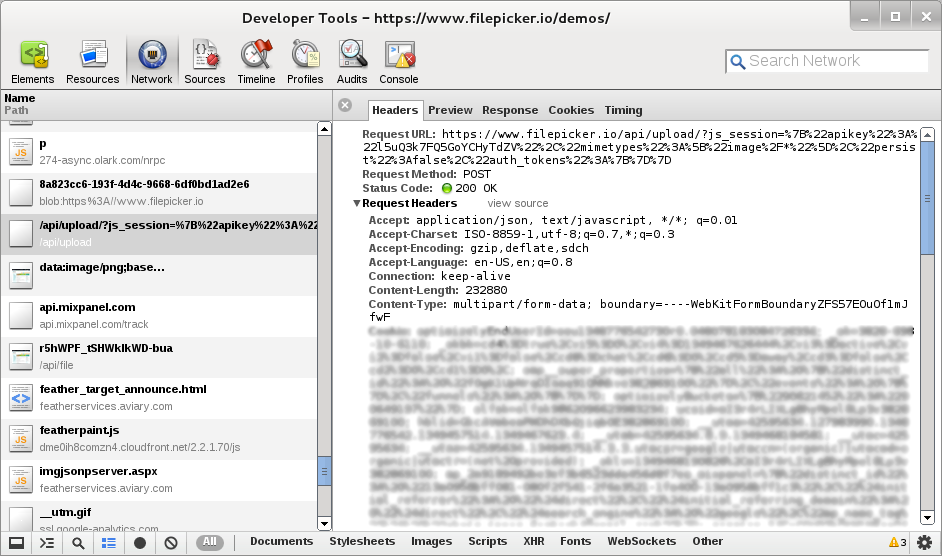
After some analysis it seems that getFile() makes a AJAX call that:
- Requests https://filepicker.io/api/upload/
- Passes a URL-encoded GET parameter named “js_session”
- Sends the file as POST paramater named “fileUpload”
Running a Javascript unescape() gives us a bit of insight into the js_session object:
{
"apikey" : "l5uQ3k7FQ5GoYCHyTdZV",
"mimetypes" : ["image/*"],
"persist" : false,
"auth_tokens" : {}
} The request includes the MIME type (the server checks the MIME of the file), API key, and some other options. The server then responds with this JSON object:
{
"result" : "ok",
"data" : [{
"url" : "https://www.filepicker.io/api/file/r5hWPF_tSHWkIkWD-bua",
"data" : {
"size" : 232662,
"type": "image/png",
"filename": "Screenshot from 2012-09-17 21:01:49.png"
}
}]
} The entire process is relatively simple. So, I wondered, what happens if I preform the same request with my own script?
$ wget http://placehold.it/400x400 -q -O pic.gif
$ ./upload2fp.py pic.gif
{"data": [{"url": "https://www.filepicker.io/api/file/v3gIv0tEQ9-7mwsSXSjB", "data": {"size": 1622, "type": "image/gif", "filename": "pic.gif"}}], "result": "ok"}
$ eog https://www.filepicker.io/api/file/v3gIv0tEQ9-7mwsSXSjB 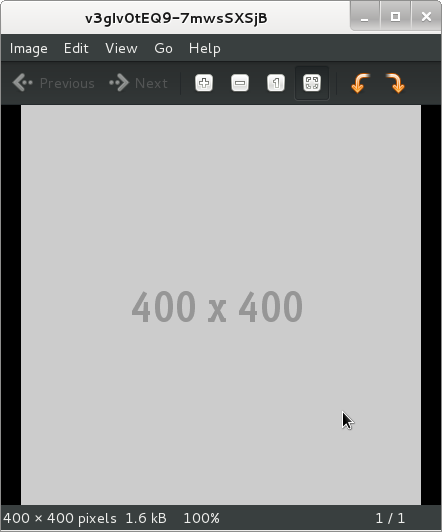
Successfully, using a script that makes the same requests, I upload a placeholder image and then download it to verify it worked.
Since we send the MIME type limiter in the request, by removing it we can theoretically upload any file type we like.
Let’s give it a shot?
$ dd if=/dev/urandom of=random.bin bs=1M count=2
2+0 records in
2+0 records out
2097152 bytes (2.1 MB) copied, 0.347794 s, 6.0 MB/s
$ ./upload2fp.py random.bin
{"data": [{"url": "https://www.filepicker.io/api/file/OAxC4uTYQE-khZXk8Jls", "data": {"size": 2097152, "type": "application/octet-stream", "filename": "random.bin"}}], "result": "ok"}
$ wget https://www.filepicker.io/api/file/OAxC4uTYQE-khZXk8Jls -q -O random2.bin
$ diff random2.bin random.bin
$ We take advantage of some linux devices to generate a 2MB file of random data, then upload it. After doing that, we download it and verify that it is identicle. And it worked perfectly.
So we can upload 2MB files of any file type. What exactly are the size limits then?
5MB? No.
10MB? No.
50MB? No.
100MB? Nope.
200MB? Still appears no.
I stopped testing after uploading a 419MB file of random binary data, then downloading and comparing that the upload was successful. It’s important to remember that with someone’s API key, all of this data is shoved directly into their Amazon S3 bucket and downloaded on their dollar.
The Problem
The folks are Filepicker.io are very clearly aware that someone might use a script to upload files instead of their library. In fact, the CEO and Founder actually mentioned that this particular script was a “cool little tool” (which it is). This makes me wonder if I am actually missing some particularly powerful security features they have, or if they just didn’t think of ways in which this might be severely abused. So I checked the “Developer Home” interface that they provide.
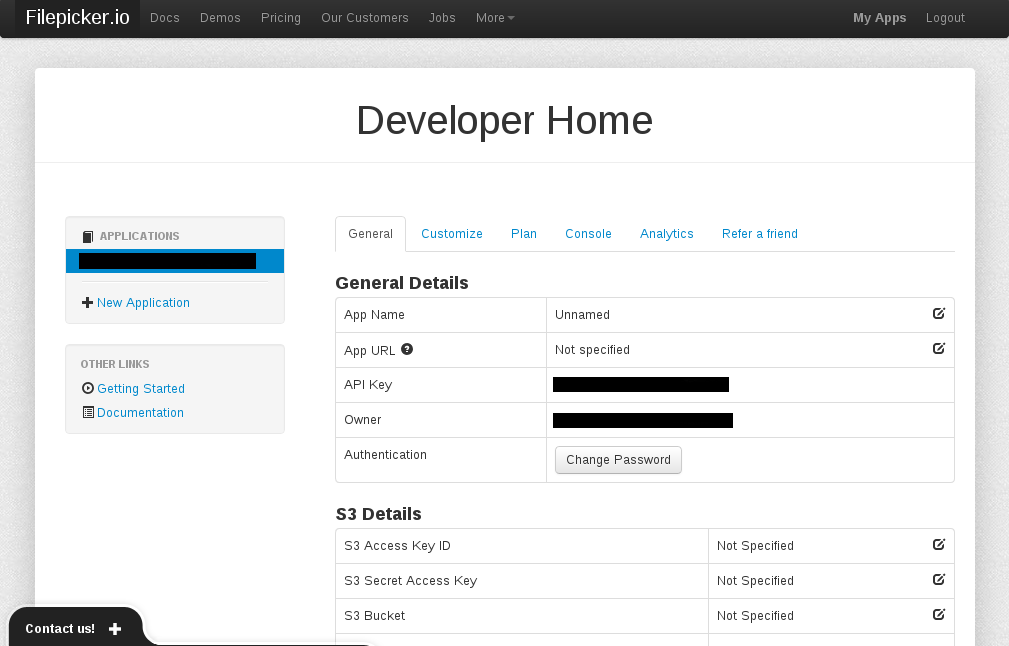
As you can see, it does appear that they provide a security measure. The App URL, as they describe, sounds like it checks the referer of the client. If they don’t appear to be making the request from your app’s URL, they deny the upload. The only problem is that HTTP referers are sent just as plain headers, meaning they can be easily spoofed. It is trivial to fake your referer, and to test this I added it directly into my Python upload script.
The Solution
Filepicker is an awesome tool and great demonstration of how the cloud should be done. However, unless I am missing some element of their security measures that is not apparent to me, there is some serious problems. Design wise, this is a relatively simple solution for the guys at Filepicker. Under each API Key in the Developer Home, adding the ability for a developer to set the max file size and MIME type in the server side admin panel, not in the client side Javascript call, will solve this.
The possible abuses for this are endless. Pirates and Hackers could be storing their files in your S3 bucket, and others downloading them on your dollar. Unfortunately, in addition the owner of the bucket might quite possibly be held accountable for legal implications and copyright damages. Hopefully the Filepicker team will be quick to either get this fixed, or point out where I made my mistake ;)
The finish script is on Github.
Updated October 11, 2012: Added email from Filepicker’s CEO
Updated April 5, 2015: Added syntax highlighting